第 3 章 R语言基础
世界上本没有路,有了腿便有了路。— 让子弹飞
3.1 R语言简介
R语言来自S语言,是S语言的一个变种。S语言由Rick Becker, John Chambers等人在贝尔实验室开发,著名的C语言、Unix系统也是贝尔实验室开发的。R是一个自由软件,GPL授权,最初由新西兰Auckland 大学的Ross Ihaka 和 Robert Gentleman于1997年发布,R实现了与S语言基本相同的功能和统计功能。现在由R核心团队开发,但全世界的用户都可以贡献软件包。
R语言最常用的编辑器是RStudio,由Posit公司(不以盈利为目的社会企业)2011年发布的一种跨平台集成开发环境。
3.2 R语言的特点
R语言具有以下特点:
- 自由软件:免费、开放源代码,支持各个主要计算机系统
- 完整的程序设计语言-基于函数和对象,可以自定义函数,调入C、C++、Fortran编译的代码
- 高级语言:代码像伪代码一样简洁、可读
- 交互性:强调交互式数据分析,支持复杂算法描述,图形功能强,出色的文学式编程组件
- 社群:统计科研工作者广泛使用R进行计算和发表算法,R有上万软件包!
- 面向数据分析的对象,具有完善的数据对象,如向量、矩阵、因子、数据集、图、树等,支持缺失值
- 统计软件:实现了经典的、现代的统计方法,如参数和非参数假设检验、线性回归、广义线性回归、非线性回归、可加模型、树回归、混合模型、方差分析、判别、聚类、时间序列分析等
总而言之,R是一个不错的编程语言,可以独立完成整套工作流程。R是统计分析、数据可视化与文学式编程等方面的最佳工具!
3.3 R与Rtudio的安装
3.3.1 安装R
从R语言官网(https://www.r-project.org/)根据自己的操作系统选择对应R版本。亦可通过%60apt%60或%60brew%60命令下载。
3.3.2 在WSL上安装R语言
对于Windows读者,在Windows Subsystem for Linux (WSL) 上安装R语言,有两种安装方法:使用包管理器安装和从源代码编译安装。
- 替换软件源列表
在开始安装前,建议先更换软件源,以提高下载速度和稳定性。以下是更换软件源的步骤:
第一步、打开WSL
第二步、备份原有的sources.list文件:
sudo mv /etc/apt/sources.list /etc/apt/sources.list.bk第三步、使用新的源列表(阿里云的源):
首先,打开/etc/apt/sources.list文件进行编辑:
sudo nano /etc/apt/sources.list然后,复制并粘贴以下内容到该文件(注意你的系统版本,此处默认为Debian):
deb http://mirrors.aliyun.com/debian/ bookworm main non-free contrib
deb-src http://mirrors.aliyun.com/debian/ bookworm main non-free contrib
deb http://mirrors.aliyun.com/debian-security bookworm-security main contrib non-free
deb-src http://mirrors.aliyun.com/debian-security bookworm-security main contrib non-free
deb http://mirrors.aliyun.com/debian/ bookworm-updates main contrib non-free
deb-src http://mirrors.aliyun.com/debian/ bookworm-updates main contrib non-free第四步、 保存并关闭文件。
如果你使用的是nano编辑器,可以通过按Ctrl + X,然后按Y,最后按Enter来保存更改。
第五步、更新软件包列表:
sudo apt-get update
sudo apt-get upgrade- 使用包管理器安装R
第一步、安装R
sudo apt install r-base第二步、验证安装
检查R版本以确认安装:
R --version第三步、启动R
将进入R的交互式界面。
- 从源代码编译安装R
第一步 安装R的构建依赖
sudo apt-get build-dep r-base第二步、选择R版本并下载源代码(此处选择3.6.2)
RVERSION=3.6.2
mkdir src
cd src
wget https://mirrors.tuna.tsinghua.edu.cn/CRAN/src/base/R-3/R-3.6.2.tar.gz
tar zxf R-${RVERSION}.tar.gz
cd R-${RVERSION}第三步、配置、构建和安装
./configure --prefix=$HOME/R/${RVERSION} --enable-R-shlib
make
make install第四步、清理源代码(可选)
cd ..
rm -r R-${RVERSION}第五步、添加R到PATH环境变量
cd
cp .bashrc .bashrc-R.bk
echo -e "
# add R $RVERSION to PATH
export PATH=$HOME/R/${RVERSION}/bin:\$PATH
" >> .bashrc
. .bashrc选择适合你需求的安装方法:包管理器安装适合大多数用户需求,源代码编译安装允许更多自定义配置但过程更复杂。
3.3.3 R安装RStudio
从Rstudio官网(https://posit.co/products/open-source/rstudio/)下载Rstudio并安装。打开RStudio可以看到下列界面

共有四个工作区域,“脚本区域”用于编辑脚本文件;“命令窗口”用于返回代码运行结果,也可以直接运行代码;“变量窗口”显示R内部环境;“环境等窗口”显示外部环境。
3.3.4 组织R代码的三种方式
第一种是命令窗口写代码。写代码时,按Shift+Enter键为换行,按Enter键直接为执行,代码执行后便不可修改。因而在命令窗口中写代码一般只适合代码极为简单、与上下文代码不是一个整体的情况,比如试验某行代码的功能、查看帮助文档、检查某个值等。
第二种是脚本写代码。在脚本中的代码可以反复修改执行,保存为.R文件,是最常用的写代码的地方。写完之后,用光标选中需要执行的代码,点击上方的Run按钮,或按快捷键Ctrl+Enter,即可执行选中部分的代码。如果需要全部执行,全选(Ctrl+A)后按Ctrl+Enter。或者按Ctrl+Shift+Enter。如果光标没有选中任何代码,按Ctrl+Enter后,会执行光标所在那一行的代码
第三种是RMarkdown写代码。使用文学式编程方式制作一体化数据分析报告。
3.4 R对文件和路径的相关操作
在R语言内部可以文件与路径进行一系列操作,这些函数都在base包中。
3.4.1 路径操作
3.4.1.1 查看与修改路径
工作路径(working directory)指的是R在系统做工作的位置,R会默认在工作路径中读入写出数据。初学者往往会忽略工作路径的设置,从而给代码和数据管理带来制造混乱,我们建议每个R项目都使用独立的工作路径。下面的组命令可以对工作路径进行查看与修改。
# 赋值一个工作路径变量,该路径应该是已经存在的,如果不存在需要使用下接中的dir.create函数创建
mypath = "~/myRworkingdir"
# 为了确保路径存在,可以先查看其是否存在
file.exists(mypath)
# 查看当前的工作路径
getwd()
# 设定mypath为工作路径
setwd(mypath)
# 查看当前目录的子路径
list.dirs()
# 查看当前目录的子目录和文件
dir()
# 查看特定路径的子目录和文件
dir(mypath)
# 列出目录下包括隐藏文件在内的所有的目录和文件
dir(mypath,all.files=TRUE)
# 只列出以字母R开头的子目录或文件
dir(mypath,pattern='^R')
# 查看当前目录权限
file.info(".") 3.5 数据类型
任何计算机语言要解决的第一个问题都是以什么样的方式来储存数据。R作为一个高级语言,我们可以从研究应用的角度来理解其数据类型。这也是贯穿本书的立场。
回忆一下,我们在社会科学研究设计中学到的知识,研究变量可以分为:定类变量、定序变量、定距变量和定比变量。分别对应了R语言里面的字符型、逻辑型和数值型数据。
| 变量类型 | 数据类型 |
|---|---|
| 定类变量 | 逻辑型、字符型 |
| 定序变量 | 逻辑型、字符型 |
| 定距变量 | 数值型 |
| 定比变量 | 数值型 |
| 缺失值 | NA |
3.5.1 数值型
数值型可以分为整数型和浮点型,实际上操作中,大部分时间我们可以忽略这两者之间的差异。数值型直接使用数字表示,并可以进行数值运算。
## [1] 1## [1] 5## [1] 3.1415933.5.2 逻辑型/布尔型
逻辑型有两个值真和假,用TRUE和FALSE表示(必须大写,也可用首字母表示)。其用于表示逻辑运算的结果,在后续的数据取子集操作中会大量使用。
## [1] TRUE## [1] FALSE## [1] TRUE## [1] FALSE3.5.3 字符型
字符型是R储存文本信息的数据类型,字符型数据用"或者'引起来。
## [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S"
## [20] "T" "U" "V" "W" "X" "Y" "Z"## [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"## [1] "January" "February" "March" "April" "May" "June"
## [7] "July" "August" "September" "October" "November" "December"paste函数可以将多个字符粘贴为一个字符,粘贴的分隔符由sep参数指定
## [1] "Hello+World"nchar函数可以计算字符的长度
## [1] 11注意,不同于Python,R总的字符是一个整体,无法直接取出某个元素。需要使用substr来实现该功能。
## [1] "Hell"3.5.5 数据类型判断与转换
R提供了内置的is.函数和as.函数来对数据类型进行判断与转化。
| 函数 | 作用 |
|---|---|
is.numeric |
数值型判断 |
is.integer |
整数型判断 |
is.logical |
逻辑型判断 |
is.character |
字符型判断 |
is.na |
NA判断 |
as.numeric |
转换为数值型 |
as.integer |
转换为整数型 |
as.logical |
转换为逻辑型 |
as.character |
转换为字符型 |
特别注意不同类型之间的转换并不是等价的。除NA外所有类型都可以转换为字符型,但是只有本身就是”数字”的字符型才可以转化为数值型。任何数值型都可以转为逻辑型,数字0会转换为FALSE,其他数字会转换为TRUE;反过来,TRUE会转换为1,FALSE会转换为0。
课堂练习
- 如何将3.141592657 转换成 character
- 如何将3.141592657 转换成 logical
- 如何判断”hello world”是否是一个character
- 如何判断一个NA是否是缺失值
3.6 变量
程序语言中的变量用来保存输入的值或者计算得到的值。在R中,变量可以保存所有的数据类型,比如标量、向量、矩阵、数据框、函数等。
R使用<-或者=变量赋值,例如
任何一个变量都有两个属性,名字与取值,上述变量名为”x”,取值为”3.14159”。
在名字空间(namespace)中会储存一个x,当代码使用x是计算机会调取其取值3.14159。
还可以使用get和assign函数来提取变量的取值,以及为变量赋值,get("name")是提取名字为name的数据的值,assign("name",value)是将value赋值给name。这一操作目前看起来是多此一举,但是在后续遇到多此进行取值、赋值操作时候,这两个函数发挥妙用来减少重复代码。
## [1] 3.14159## [1] 3.141593.7 数据结构
针对数据分析的要求,R语言预先定制好了一些数据结构,包括向量、矩阵、数据框、列表等。如果把数据类型比作乐高积木的基础组件,那数据结构便是在基础组价之上搭建好的具有特定功能的组合要件。

3.7.1 向量
3.7.1.1 向量生成
向量是将若干个数据类型相同的值存储在一起,c函数用于生成与拼接向量。
## [1] 1 2 3 4## [1] 2 3 4 5## [1] 1 2 3 4 2 3 4 5## [1] "1" "2" "c"seq()用于生成等差数数列向量,rep()用于生成重复元素向量
## [1] 1 5 9## [1] 1 2 3 4 5 6 7 8 9 10## [1] "a" "a" "a" "a"特别地,NA可作为任何向量的元素而不会对向量类型造成干扰,这也是符合我们实际数据处理习惯的一种方式。
课堂练习
如何生成一个空向量
如何生成一个空的字符向量
3.7.1.2 向量类型转换与运算
数据类型转换函数完全适用于向量。
## [1] "1" "2" "3" "4"对向量进行数值运算等同于对向量的每个元素进行运算。
## [1] 2 3 4 5## [1] 3 5 7 9## [1] 2 6 12 20课堂练习
计算v1 + v3,并解释原理。(注意,当两个向量不等长时,会自动补长短向量)
特别地,向量还可以进行集合运算,
| 集合运算符 | 含义 |
|---|---|
%in% |
属于 |
intersect |
取交集 |
union |
取并集 |
setdiff |
取补集 |
## [1] FALSE TRUE TRUE TRUE## [1] 2 3 4下面列出一些常用函数
| 函数 | 含义 |
|---|---|
length |
向量长度 |
unique |
向量去重复 |
rev |
向量翻转 |
sort |
向量排序 |
order |
向量元素的顺序 |
sum |
求和 |
cumsum |
累计和 |
mean |
平均数 |
sd |
标准差 |
var |
方差 |
min |
最小值 |
max |
最大值 |
range |
取值范围 |
prod |
所有元素乘积 |
duplicated |
元素是否重复 |
prod |
所有元素乘积 |
any |
是否有TRUE(针对逻辑向量) |
all |
是否所有都是TRUE(针对逻辑向量) |
which |
TRUE对应的下标(针对逻辑向量) |
all.equal |
两个向量全等 |
paste |
将多个字符粘贴为一个字符,分割符由collapse参数指定 |
which.min |
最小值的下标 |
which.max |
最大值的下标 |
3.7.1.3 向量切片
可以直接用[]操作符对向量进行切片,即取出子集。[]内的元素称为下标。
首先是数字下标,例如用v1[1]表示取出向量v1的第一个元素。特别地,R语言的元素是从1开始编号的,这更符合人类的直觉。Python和c语言则不同,元素是从0开始编号的,即第一个元素用0表示,这更符合计算机的直觉。在切换不同工具时,需要注意这个细节,以免出现不可察觉的错误。
其次,[]操作符中不仅可以使用数字,还可以使用逻辑向量来进行切片,例如
## [1] 1 2这事实上启发了我们可以更加灵活的来对向量进行切片。具体来说,我们可以通过生成一组逻辑向量的方式来切片,例如如果我们想取出v1中大于2的元素,则可以:
## [1] 3 4## [1] 3 4课堂练习
- 取出v1的第2和第3个元素
- 取出v1的最后一个元素
- 取出v1的倒数第二个元素
- 取出v1中整除3的元素
- v1[-1]会返回什么结果,有何启示?
- v1[5]会返回什么结果,有何启示?
- v1[] <- 99 与 v1 <- 99 有何不同?
3.7.2 因子
因子是一类特殊的向量,用于储存分类变量。
每个因子都有水平标签(levels),缺省状态下,以字母序排列,有时候(例如画图时候,为了调整图例的顺序)我们需要对因子水平顺序进行调整,此时可以使用levels函数。
因子实际上使用数值型来储存字符型的一种向量,这样做的显而易见的好处是可以节约储存空间,从而优化运算速度。因此,因子可以转换为数值型。
## [1] 2 1 2 2 1需要注意的是,这里转化成的数字是自然序的,如果一个数值型向量被误存为因子型,保险的方式是将其先转换为字符型,然后再转换为数值型,否则有可能出错。
## [1] 1 2 3## [1] 1 10 23在回归中如果我们希望把一个数值变量当成分类变量使用时,可以直接在回归公式中指定其为factor,例如年份的固定效应。y ~ x + factor(year)
3.7.3 矩阵
矩阵是二维的数值型数据结构,可以看成是列向量的按行组合,或者行向量的按列组合。矩阵底层实际按列存储成一个向量。矩阵主要被用在科学计算上,而这是Python擅长的工作。因此,绝大部分时间我们都不会在R中使用到矩阵,这里就简单介绍一些矩阵的基本知识即可。不是我们的重点
3.7.3.1 矩阵的生成
matrix 函数用于生成矩阵
M1 <- matrix(c(3:14), nrow = 4, byrow = TRUE)
M2 <- matrix(c(2,6,5,1,10,4),nrow = 2,ncol = 3,byrow = TRUE)diag 函数用于生成对角矩阵
3.7.3.4 矩阵的切片
矩阵使用[]符号来取出相应未知的元素组成新矩阵。由于矩阵是二维的,因此切片下标也需要时二维参数,用逗号分割。
## [,1] [,2] [,3]
## [1,] 12 13 14
## [2,] 9 10 11
## [3,] 6 7 8
## [4,] 3 4 5## [,1] [,2] [,3]
## [1,] 5 4 3
## [2,] 8 7 6
## [3,] 11 10 9
## [4,] 14 13 123.7.4 数据框
数据框(data.frame)是R语言最伟大的数据结构,也是处理表格数据的最佳工具。基于数据框开发出来的tibble以及data.table构成了R语言处理表格数据的强有力工具箱。Python的pandas正是对data.frame的模仿,因此我们在Python部分不推荐大家使用pandas来处理表格数据。
数据框是一个特殊的二维表,数据框每一列都有一个唯一的列名,长度都是相等的,同一列的数据类型需要一致,不同列的数据类型可以不一样。这样的要求是源自每一列对应了实际研究中的一个变量。
数据框式我们未来很长一段时间的主要工具。
3.7.4.1 数据框的生成
数据框使用data.frame函数生成,其可以直接把矩阵转化为数据框
注意,在旧版本的R中,在生成数据框时,R会默认把字符型向量转化为因子,如果不需要这样的转换,需要设置参数stringsAsFactors = FALSE。但是新的版本已经修改了这个参数的默认值。
3.7.4.2 数据框的行列名
与矩阵一样,数据框有行列名称names等价于colnames,rownames用于修改行名称,列名称有重要的用途。
可以在生成数据框时,直接指定列名称,这一作法更加被鼓励
3.8 数据读写
在实际操作中,我们很少通过代码赋值的方式在生成原始数据。数据往往储存在诸如csv等格式的数据文件中。R语言也有专属的数据文件RData来储存数据。本节我们介绍下常见数据格式的读写。
按照数据的使用方式,我们可以将数据进一步分为通用数据与非通用数据,前者不限于特定的编程工具,在程序世界中扮演着”通用货币”的角色,是可以跨语言跨工具使用的标准数据,例如txt,csv,xml,json,
hdf5等;后者则是特定语言使用的数据,在一定程度上也可以跨语言使用,但是跨语言使用时经常伴随有信息的错误与损失,常见的非通用数据有dta(Stata),xls(MS
Excel),spv(SPSS),
RData(R)等。RStudio在使用非通用数据时,可以从Import Dataset下拉菜单中选择相应的选项。在网络通信中,通用数据是主角。
3.8.1 csv文件
csv文件指的是逗号分隔值(Comma-Separated Values)文本文件。以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符(tsv)。
csv文件可以用MS Excel直接编辑,读写简便,跨平台。缺点是以表结构为基础,灵活性较差。
我们推荐使用readr::read_csv函数对csv文件进行读入。
课堂练习
取出上海交通大学的论文数据
计算上海交通大学2022,2021,2020年分别发表了多少ssci/sci论文
计算上海交通大学2022年发表论文最多的三个学科
计算上海交通大学2020-2022年每个学科平均发表论文的数量
3.8.2 HDF5
HDF5是Hierarchical Data Format(HDF)第5代的简称,起源于高性能计算领域,目前标准由非营利组织The HDF Group1组织开发和维护。其优点在于
- (1)原始表示:数据不必转换成文本,不涉及到转换误差;
- (2)自我描述:数据类型直接写在文件中,可以被自动识别;
- (3)跨语言:支持所有主流语言,有多重查看器
但是其缺点在于并非人类直接可阅读的数据格式,且对ASCII之外的字符支持没有标准,不保证可以准确处理中文。
HDF5由数据集(Dataset)、组(Group)以及元数据(Metadata)组成。数据集用于储存多维数组;组是数据集的容器,并且可以嵌套;元数据则用于描述数据集或者组的特征,例如数据名称,数据类型等。
在R语言中使用hdf5r包2来读写HDF5数据,这里我们简单介绍一下hdf5r的基本操作。想更深入了解HDF5数据格式的读者可以直接到The
HDF
Group官网阅读相关文档。想了解更多hdf5r包的读者可以自学其官方教程3
在下面的代码中,我们通过H5File$new命令可以创建一个新的h5文件,通过create_group函数可以创建新的组,然后我们将数据mtcars放入分组,最后再通过close_all()关闭文件。
library(hdf5r)
library(datasets)
file.h5 <- H5File$new("hz.h5", mode = "w")
mtcars.grp <- file.h5$create_group("mtcars")
mtcars.grp[["mtcars"]] <- datasets::mtcars
file.h5$close_all()此时在工作路径中便生成了一个h5文件”hz.h5”,我们可以在命令行中通过python3-tables的vitables命令与hdf5-tools的h5dump命令查看HDF5文件内容。
通过H5File$new亦可以读入h5文件,然后通过names函数查看文件内的分组与数据集,并可以通过[[]]取出取出数据
## [1] "mtcars"3.8.3 XML
XML(Extensible Markup Language),-可扩展标记语言-是专门设计用来传输数据的标记语言。R中我们使用XML包读入XML数据,
## <?xml version="1.0" encoding="UTF-8"?>
## <publications dataset="scad-zbmath-01-limited-access">
## <publication id="zbmath:0790.73063">
## <title>Torsional vibrations of nonhomogeneous magnetostrictive elastic circular cylinder</title>
## <venue>Int. J. Math. Math. Sci. 17, No.1, 181-185 (1994).</venue>
## <year>1994</year>
## <classification>74F15 74H45</classification>
## <keywords>circumferential magnetic field; axial current; longitudinal magnetic field; frequency equation; displacement; stress</keywords>
## <abstract>This paper is concerned with the torsional vibrations of a nonhomogeneous magnetostrictive elastic cylinder. The cylinder is subjected to the action of a circumferential magnetic field produced by an axial current of constant density, and the deformation of a magnetostrictive cylinder is produced by a constant longitudinal magnetic field. The frequency equation is determined, and the displacement and stress components are numerically calculated with graphical presentations.</abstract>
## <authors>
## <author name="Debnath, Lokenath" shortname="Debnath, L." id="debnath.lokenath"/>
## </authors>
## </publication>
## <publication id="zbmath:0805.73022">
## <title>Torsional wave propagation in an orthotropic magneto-elastic hollow circular cylinder</title>
## <venue>Appl. Math. Comput. 63, No.2-3, 281-293 (1994).</venue>
## <year>1994</year>
## <classification>74J10 74F15</classification>
## <keywords>extrema; characteristic numbers; phase velocities; first five modes</keywords>
## <authors>
## <author name="Abd-alla, Abo-el-nour N." shortname="Abd-alla, A." id="abd-alla.abo-el-nour-n"/>
## </authors>
## </publication>
## </publications>
## 标准的XML可以分为标记(Markup)与内容(Content)两类。标记通常以<开头,以/>结尾,在上面的例子中,publications以及publication都是标记。
标记也称为标签Tag,是规定XML文件结构的部分,是数据的结构。
内容又称为元素Element,是标签”标记”的部分,是数据的值。上面的例子中Torsional vibrations of nonhomogeneous magnetostrictive elastic circular cylinder便是标记title的值。
每一个标签可以拥有若干属性Attribute,属性以name=value的形式出现。每个元素中,一个属性最多出现一次,一个属性只能有一个值。例如第一个publication标记拥有一个属性id,取值为zbmath:0790.73063。
从数据结构上来说XML是树形结构,其优点在于跨平台表现优异,可以传输结构复杂的数据。因此,经常被用作通用数据标准。但是细心的读者很容易发现XML的劣势,大部分标签名都重复出现了两次。另外,仅仅从数据传输而不是数据可视化的角度来说,属性本质上也可以用标签+内容的方式来表达,而不需要单独设置。这都使得XML在传输数据方面,显得比较”笨重”,效率还有提升的空间。
3.8.4 JSON
JASON(JavaScript Object Notation,JavaScript)-Java对象表示法-是由道格拉斯·克罗克福特构想和设计、轻量级的数据交换语言,该语言以易于让人阅读的文字为基础,用来传输由属性值或者序列性的值组成的数据对象。尽管JSON起初是为JavaScript设计的,但如今早已发展成为独立于特定语言之外的通用数据格式。
R中可以使用jsonlite读写JSON文件,读入数据成为一个list
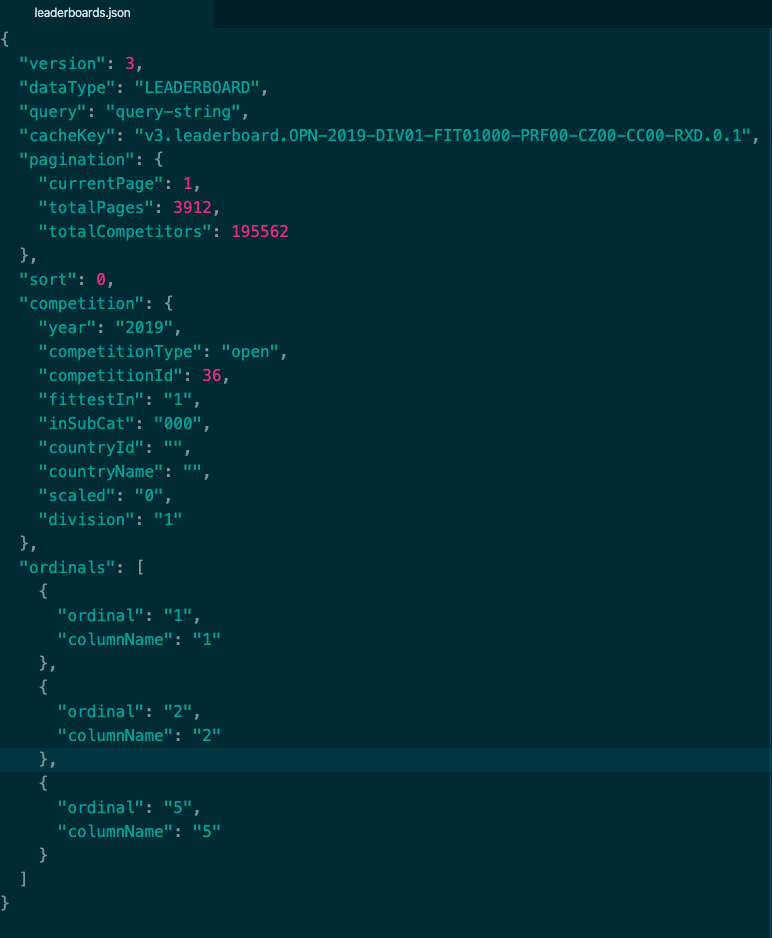
JSON由对象object与数组组成。对象(object)是一个对象包含一系列非排序的名称/值对(pair),一个对象以{开始,并以}结束。每个名称/值对之间使用:分割。上面的例子中"version":3就是一个对象,其名称是version,value是3。
数组(array):一个数组是一个值(value)的集合,一个数组以[开始,并以]结束。数组成员之间使用,分割。上面例子中"ordinals"对应的值便是一个数组。
JSON与XML最大的不同在于XML是一个完整的标记语言,而JSON不是。XML利用标记语言的特性提供了绝佳的延展性(如XPath),在数据存储,扩展及高级检索方面具备对JSON的优势,而JSON则由于比XML更加小巧,以及浏览器的内建快速解析支持,使得其更适用于网络数据传输领域。
3.8.5 YAML
YAML全称YAin’t Markup Language,它可以看做是JSON的进一步优化。JSON尽管已经非常简洁,但是其字符串使用的引号和花括号依然是可以简约掉的。YAML使用key: value对的形式来传递信息,使用缩进表达数据之间的层级关系(强制缩进,python的思想),同时YAML的字符串不再使用引号加以区分。以上一系列约定,使得YAML成为最简洁的数据文件。YAML被广泛引用在配置文件中。
3.8.6 专用数据文件
R语言针对各类专用数据文件设计了读写借口,具体函数如下表:
| 数据格式 | 程序语言 | 函数 | 功能 |
|---|---|---|---|
| .RData | R | load |
读入 |
| .RData | R | save ; save.image |
写出 |
| .dta | STATA | haven::read_dta |
读入 |
| .dta | STATA | haven::write_stata |
写出 |
| .sav | SPSS | haven::read_sav |
读入 |
| .sav | SPSS | haven::write_sav |
写出 |
| .sas | SAS | haven::read_sas |
读入 |
| .xpt | SAS | haven::read_xpt |
读入 |
| .xpt | SAS | haven::write_xpt |
写出 |
3.9 流程控制
现在我们学会了R语言的基本构件(数据类型与数据结构),他们好比是盖楼使用的砖块。但是为了更好的使用这些基本构件来实现更加丰富的功能,需要掌握流程控制语句。流程控制语句类似大楼的钢筋混凝土结构,构成了一段代码的骨架。流程控制语句有两种,第一种是判断语句,第二种事循环语句。
3.9.1 条件判断
条件判断语句用于程序执行的走向,当条件判断为真时,执行一套语句;当条件判断为假时,执行另一套语句。R中有两种条件判断语句,if..else以及switch。
3.9.1.1 if-else语句
if-else语句是R语言最基础的结构,其基础结构是一个二分形式:
通过对二分形式的拓展可以引入更加复杂的判断流程,可以在引入一个if判断便可以生成三个两个二分结构。
下面是一段关于“数字比大小”的程序,
## 100 is lager than 50这段代码可以扩展为逻辑更完整的程序,
m <- 100
n <- 50
if(m > n){
cat(m,"is lager than", n)
}else if(m ==n){
cat(m,"is equal to", n)
}else{
cat(m,"is smaller than", n)
}## 100 is lager than 50看到这样的代码有没有想到一个古人

3.9.2 循环
循环语句用于执行重复性的操作,循环语句加判断语句就可以完成R里面绝大多数工作了。R中提供了for,while, repeat三种形式的循环语句。R还提供了两个控制语句break与next。
循环语句的基本逻辑是,当条件判断为真时,重复执行相应的执行语句,直到条件判断为假时,退出循环。
3.9.2.1 for循环
for循环使用指标迭代器作为判断语句,其结构为:
一般来说,迭代器是一个向量,for循环执行的次数为迭代器的长度。例如,可以使用下面的代码输出前100个数字的求和。
课堂练习:
1.计算交通大学1999年到2020年的每年发表论文的数量
2.输出一份九九乘法表(提示,\t表示制表符,\n表示换行符,使用cat函数)
 #### while循环
#### while循环
while循环的条件语句是一个逻辑值,当逻辑判断为TRUE是,重复执行。注意,while循环不限制循环次数,因此,特别注意,需要人为设定跳出条件,否则循环将会无限循环(即死循环当中)。
一种方式是通过为判断语句设定跳出条件来结束循环,例如上述乘法口诀表的例子可以通过下面代码来实现。其中,指标i是一个计数器,每一次循环都自动增加1,当循环完成9次时,判断语句i <= 9返回FALSE,跳出循环。
i <- 1
while(i <= 9){
j <- 1
while (j <= i){
cat(j, "*", i, "=", i*j, "\t",sep = "")
j <- j + 1
}
cat("\n")
i <- i + 1
}结束循环的另一种方式是使用break命令,其作用的是跳出当前循环,并运行循环后的语句。例如,上述代码等同于下列代码。while(1)意味着每次都会进入循环,但是当i>9时,触发break命令,从而跳出循环。
i <- 1
while(1){
if(i>9){break}
j <- 1
while (j <= i){
cat(j, "*", i, "=", i*j, "\t",sep = "")
j <- j + 1
}
cat(“\n")
i <- i + 1
}特别地,与break命令相似的还有一个next命令,不同之处在于next命令跳出循环后,会回到循环的条件判断语句运行,而非执行循环之后的语句。
例如,下面代码可以打印除了大写字母D之外的其他大写字母。
## [1] "A"
## [1] "B"
## [1] "C"
## [1] "E"
## [1] "F"
## [1] "G"
## [1] "H"
## [1] "I"
## [1] "J"
## [1] "K"
## [1] "L"
## [1] "M"
## [1] "N"
## [1] "O"
## [1] "P"
## [1] "Q"
## [1] "R"
## [1] "S"
## [1] "T"
## [1] "U"
## [1] "V"
## [1] "W"
## [1] "X"
## [1] "Y"
## [1] "Z"3.9.2.2 repeat循环
上述循环的while(1)命令可以用更简洁的repeat命令替代。
i <- 1
repeat{
if(i>9){break}
j <- 1
while (j <= i){
cat(j, "*", i, "=", i*j, "\t",sep = "")
j <- j + 1
}
cat(“\n")
i <- i + 1
}课堂练习
- 数字炸弹游戏
编写一段代码实现猜数字的游戏:
- 随机生成一个1-100之内的数字(sample函数)
- 用户输入一个数字(readline函数)
- 根据输入的数字做出判断,并输出提示
- 若数字大于被猜的数字,则输出提示猜大了,并让用户继续输入新的数字
- 若数字大于被猜的数字,则输出提示猜小了,并让用户继续输入新的数字
- 若数字大于被猜的数字,则输出提示猜对了,并且结束游戏
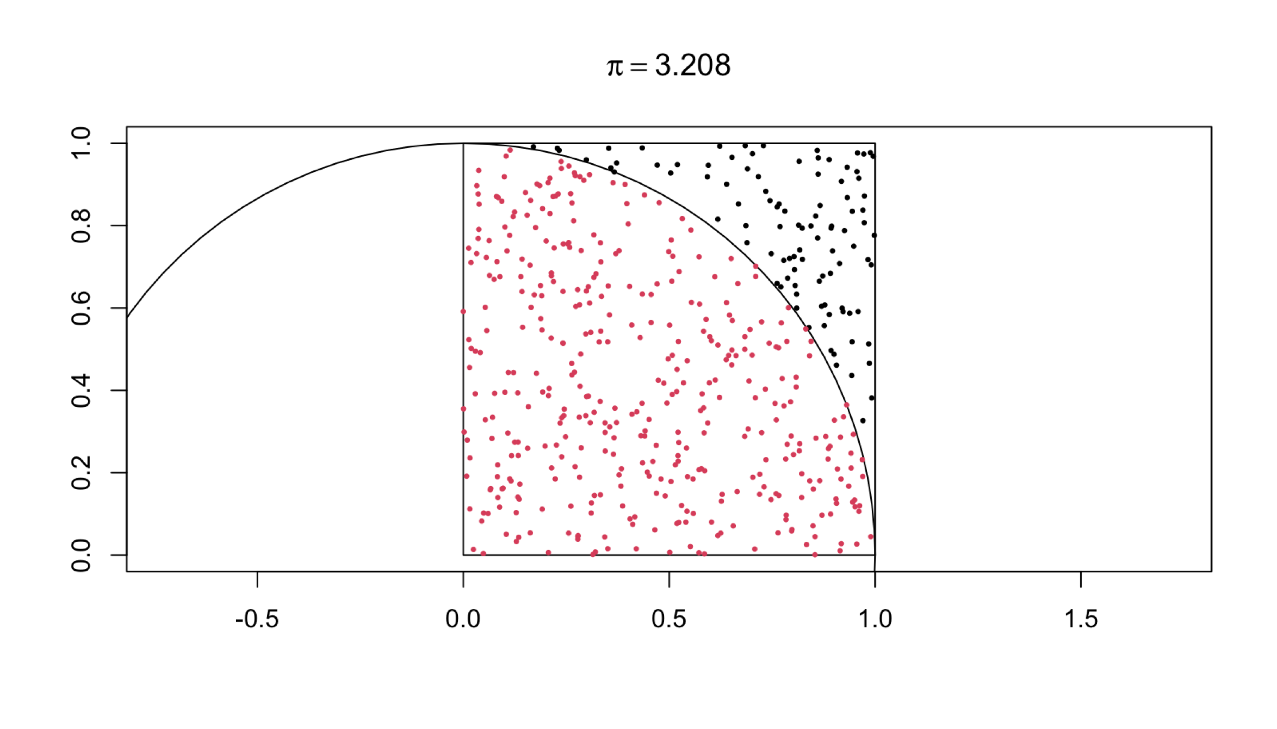
- 祖冲之一日体验卡
应用模拟的思路计算圆周率
- 兔子数列问题
一般而言,兔子在出生两个月后,就有繁殖能力,一对兔子每个月能生出一对小兔子来。如果所有兔子都不死,那么一年以后可以繁殖多少对兔子?

通过for循环,得到第n月的兔子数量。
3.10 函数与包
通过前面的学习和练习,细心的读者应该已经发现,我们在编程的时候经常会重复自己的代码,例如,在数字炸弹游戏中我们重复使用了比大小的代码;在菲波那切数列时,要能不断修改循环的次数,来实现求和?
这种重复代码存在诸多弊端,不够简洁,移植性差,违反了一次原则。在重复过程中很容易出错,特别没有腔调,不优雅。
在几乎所有的计算机语言中,都会通过函数来将代码封装在一起实现类似的功能。定义函数后,可以在后续代码中通过调用函数的方式,实现代码复用。
编程时,将任务拆解成相互独立的模块,并将不同的模块定义成函数,可以降低程序的复杂性,增强可读性。同时,函数内部的局部变量只在函数运行时调用,避免了不同模块之间的交叉影响,符合正交原则。
3.10.1 函数的定义与调用
R语言通过function关键字来定义函数,具体定义方式如下:
其中,function_name为自定义的函数名,arg1等为函数的参数,相当于是函数的自变量。函数的参数可以有任意多个,或者零个。return命令指定了函数的返回值,如果return命令时,以函数内表达式的最后一个表达式为返回值。
上一节练习题的兔子数量问题,可以定一个如下函数来计算:
Fibonacci <- function(N=10){
if(N == 1){
Fib = 0
}else if(N == 2){
Fib = 1
}else{
n1 = 0
n2 = 1
for(i in 3:N){
Fib = n1 + n2
n1 = n2
n2 = Fib
}
}
return(Fib)
}对数列基础知识了解的读者,可能已经注意到,兔子数量问题生成的就是著名的斐波那契数列。
直接使用function_name(arg)的方式可以调用已经定义好的函数,例如Fibonacci(100)可以计算第100个斐波那契数列的元素。当存在多个参数时,可以按顺序调用参数,或者通过指定参数名称=参数值的方式来调用函数。为了增强代码的可读性,我们建议使用后者来调用参数。
实际上,调用函数的方式我们在前文中已经使用了。
课堂联系
设计一个函数实现数字炸弹游戏
3.10.2 变量作用域
函数会把R语言占用的运算环境分成两个部分,函数外环境被称为全局环境,函数内环境被称为局部环境。
全局环境可以在Rstudio的“Environment”视窗中看到,使用ls()函数可以查看全局环境中的变量,使用rm函数可以删除相应的变量,rm(list = ls())会直接清空全局环境。
函数内局部环境中的变量被称为局部变量,函数定义时所有的局部变量都不会实际生成,只有在函数被调用时,局部变量才会生成,并且随着函数调用的结束释放。当局部变量与全局变量同名时,函数调用不会改变全局变量。
例如:
## 局部环境中global_x为 3## 全局环境中global_x为 1 2 3在函数内部如果要修改全局变量的值,用<<-代替<-进行赋值,例如
## 局部环境中global_x为 3## 全局环境中global_x为 3注意,修改全局变量容易造成不易察觉的错误,一般情况下,不建议这样写代码。
3.10.3 函数模块化
当代码中使用的函数非常冗长时,不仅会影响代码的结构与可读性,更会给代码调试工作带来额外的负担。此时,可以将函数模块化,然后单独储存在.R文件中,随后可通过source函数在主代码中调用。
例如,我们将对处理组与对照组在变量y层面进行加权T检验的代码定义为函数wttest。将其储存为wttest.R文件。
library(weights)
wttest <- function(data, y){
wtd.t.test(x = data[data$treat == 1,][y] %>% pull(1),
y = data[data$treat == 0,][y] %>% pull(1),
weight = data$weights[data$treat == 1],
weighty = data$weights[data$treat == 0],
samedata = FALSE)
}在主代码中,可以通过source函数调用wttest.R中的wttest函数。
3.10.4 包
R语言的强大之处在于其有一个全球的专业社区。其中包是社区成员将自己的代码贡献到社区的主要方式。R语言包是函数、实例数据、预编译代码的集合,包括R程序,注释文档、实例、测试数据等。
R语言包可以上传到CRAN平台,通过审核后,遍布在世界各地的R用户可以通过install.packages函数安装CRAN的包,并在代码中同构library函数加载。
期待读者们早日进入开发包贡献到R社区的阶段。
当前,R下载量最大的十个包为
## rank package count from to
## 1 1 ragg 116767 2023-11-24 2023-11-24
## 2 2 textshaping 114935 2023-11-24 2023-11-24
## 3 3 ggplot2 95446 2023-11-24 2023-11-24
## 4 4 devtools 75109 2023-11-24 2023-11-24
## 5 5 pkgdown 72893 2023-11-24 2023-11-24
## 6 6 rgl 70714 2023-11-24 2023-11-24
## 7 7 sf 63360 2023-11-24 2023-11-24
## 8 8 rlang 61007 2023-11-24 2023-11-24
## 9 9 vctrs 53075 2023-11-24 2023-11-24
## 10 10 dplyr 52183 2023-11-24 2023-11-243.11 向量化
R是一种解释型语言,在执行迭代循环时,能比编译型的速度相差几十倍。对于大规模的迭代循环,可以通过将运算向量化来提高运算效率。简单地讲,向量化就是一次性在一条CPU指令上处理多份数据。
实际上,我们应在祖冲之的例子中使用过向量化的操作。当模拟N次投针试验时,可循环N次,也可以一次性生成长度为N的向量,后者可以节约大量运算时间。
在更多情形中,可以使用apply函数家族进行向量化运算,其基本原理是将每一次迭代的执行语句封装成为一个函数,将被执行的数据(或者索引指标)存储在一个数据结构中,然后使用apply函数将该函数“应用”于特定的数据结构。根据被执行数据结构以及返回数据结构的不同,可以使用不同的apply函数。

3.11.1 apply
apply函数应用于矩阵和数据框,函数结构如下:
其中,X为数组、矩阵或数据框;Margin参数取值为1表示按行计算,取值为2表示按列计算;Fun为应用于运算的函数,可使用内置函数或自定义函数。
例如返回前10位的斐波那契数列,
## [1] 0 1 1 2 3 5 8 13 21 343.11.3 sapply
sapply是Simple lapply的缩写,相比与lapply增加了2个参数simplify和USE.NAMES。其结构为:
其中,参数simplify表示是否数组化,当值array时,输出结果按数组进行分组。参数USE.NAMES表示如果X为字符串,TRUE设置字符串为数据名,FALSE不设置。
3.12 代码风格
相信很多读者和我一样,每次回看以前写的代码就像看当年的QQ签名,浓浓的中二感。不过,我们还是得硬着头皮看,尤其是在代码第一次调试通之后,一定要再次完善代码。代码的作用本就是为了替代重复劳动,所以以后大概率还是会使用这段代码,如果代码写的一团糟,过一段时间之后,不仅别人可能看不懂,连自己也可能看不懂,有需要花大量时间去学习自己写的代码。更重要的是,代码的可读性也是可复现原则的内在要求。
本节中,我们总结了几条经验来探讨如何写出一段兼具简洁性、可读性与效率的代码,
代码要对机器友好,更要对人类友好。人类的时间是宝贵的,因此对人类友好(以代码的可读性为优化方向)的优先级高于对机器友好(以机器运算效率为优化方向);
不吝啬写注释。注释至少能保证一段时间之后,自己能看懂代码;
不要使用没意义的变量名/函数名(例如a,temp),但同时要善于使用缩写,避免变量名/函数名无限长;对不同数据,不要使用同一个变量名
一整段代码的结构组成为:加载包-数据读入-定义函数-数据变形-运算-输出;
为了简化代码,重复操作函数化,数据变形使用pipeline,代码中使用缩进与换行。当然,函数中不要使用全局数据;
向量化与并行运算,尽量使用服务器而不是自己的笔记本,用机器时间换人类时间的同时优化机器时间;
数据结构是程序设计的第一步;
及时打印计算过程的信息,避免等待焦虑,便于debug;
运算符号前后加空格等方式加强代码的结构性;
不断询问自己有没有更好的方式,优化永无止尽。
此外,Hadley Wickham在他的著作中The tidyverse style
guide中介绍了丰富的细节来帮助读者规范代码风格,同时使用styler和lintr可以快速检查与规范现有代码,Rstudio也为我们提供了自动提示代码风格的功能(如下图所示)。这些都可以帮助我们更好的规范代码。
使用Mac操作系统的读者在安装
hdf5r包的依赖bit64包时,可能会遇到报错error: unknown type name 'uint64_t',此时需要将/usr/local/include文件夹修改为其他名字,修改名字后再次安装即可。↩︎https://cran.r-project.org/web/packages/hdf5r/vignettes/hdf5r.html↩︎